
If you’re done apologizing for outages, you don’t need another vendor demo — you need reliability you can bet a quarter on. Cloud call center software should keep your lines open, your queues under control, and your reporting clean enough to run the business by numbers, not hunches. This guide breaks down the architecture, routing, coaching, analytics, and compliance moves that eliminate downtime anxiety and transform a call center into a predictable, revenue-producing engine — the exact playbook platforms like ActiveCalls are built around.
1) The Downtime Tax — And How To Zero It Out
Every “five minutes down” compounds: missed orders, churned subscribers, chargebacks, SLA penalties, lost sales meetings, and agent morale damage. The hidden cost is operational slack — the extra staffing you carry “just in case.” Kill the downtime tax and you immediately reclaim budget, leadership focus, and customer trust.
Outages fall into four buckets: carrier failure (regional telco wobble), platform failure (PBX, SBC, or database incident), access failure (VPN, SSO, browser/device), and process failure (change management, slow rollback, unclear ownership). Your software choice should neutralize all four with layered safeguards you don’t have to think about daily.
Non-negotiables if you’re serious about uptime
- Active-active edges across regions with health-checked failover measured in seconds, not war-room hours.
- Carrier diversity with automatic route re-selection (SIP OPTIONS, health probes, dynamic routing).
- Session resilience for real agents on real networks (mobile hotspots, ISP hiccups, roaming laptops).
- Change discipline: staged deploys, rollback buttons, feature flags, and postmortems that change checklists.
- Transparent telemetry: MOS/jitter/loss and incident comms visible to ops in real time.
2) What “Cloud Call Center” Must Deliver Every Day (Not Just In Sales Slides)
Cloud is not a location; it’s an operating model. The right platform turns brittle infrastructure into replaceable parts you can scale, route, and report on without begging IT for favors. Below is a compact matrix of the daily failure modes you will face, the metric that reveals them early, and the fix that actually holds.
3) Routing That Ends Missed Calls (and Keeps Execs Out of the Queue)
Routing is your throttle. Get it right and customers feel “instant,” agents feel calm, and your finance team sees cost/contact fall while revenue/contact rises. Get it wrong and you create 25-minute waits that no script can recover from. The engine: intent-first IVR, skills-based ACD, priority queues, stickiness with fallbacks, and call-back windows that are real, not “we’ll call sometime.”
Intent-first IVR
Menus represent work types (“Start a new order,” “Check an order,” “Cancel/returns,” “Billing,” “Technical support”), not departments. Fewer layers, plain language, and a zero-key escape prevent IVR rage while still deflecting low-value calls.
Skills-based ACD
Route by language, product line, entitlement, and current backlog. SL is a volume problem until it becomes a routing problem; when you see one intent consuming 40% of the lines, you don’t lecture agents — you reprioritize and reallocate capacity.
Callback discipline
- Offer callbacks the moment ASA > threshold; don’t wait for pain.
- Use windowed callbacks (“between 1:30–2:00 PM”) and keep your promise; re-queue with priority when the clock hits.
Outbound throughput without spam flags
- Predictive when you have big lists and volatile connect rates.
- Power when contactability is steady or compliance windows are tight.
- Preview when context trumps speed (B2B, upsell, collections).
- Pace by live connect rate, rotate verified CLIs, keep STIR/SHAKEN A.
Platforms like ActiveCalls wire these controls into one page so supervisors actually use them in the hour they matter, not the week after.
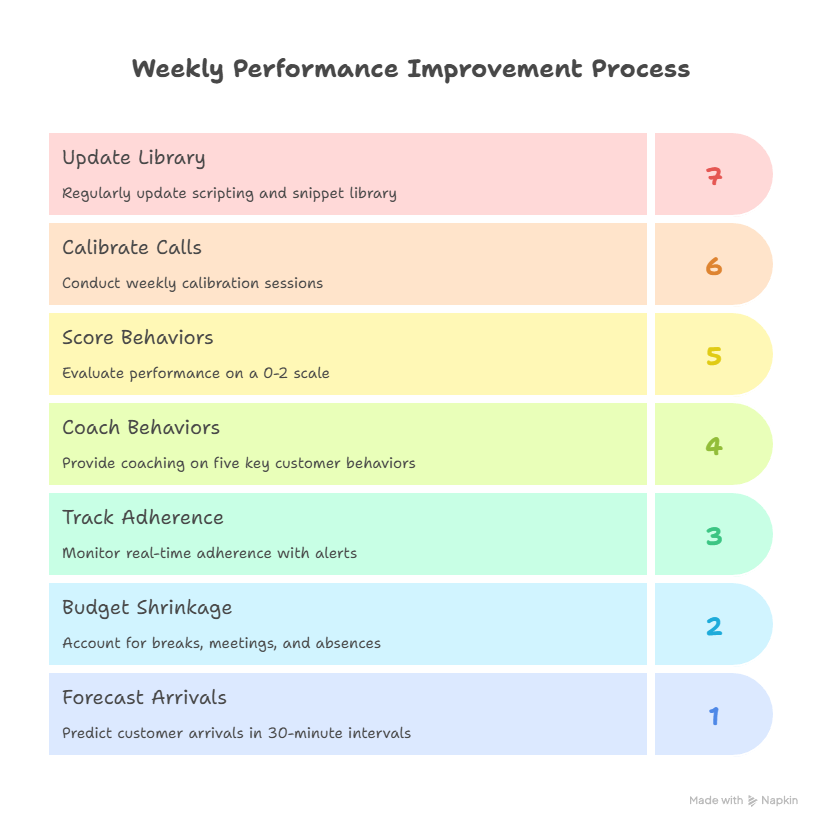
4) Workforce, Coaching & QA — Weekly Cadence That Moves Numbers
High performance is not mysterious. It’s a simple operating rhythm teams keep no matter who is on vacation. Forecast arrivals by 30-minute intervals and staff to target SL. Budget shrinkage honestly (breaks, meetings, training, absence). Track adherence in real time with alerts, not a Friday spreadsheet. Then coach to the five behaviors customers feel.
The five behaviors
- Greet/Verify — accurate profile and rapport in the first 20 seconds.
- Discover — confirm intent, root causes, constraints.
- Resolve — execute the fix (or best next step if gated).
- Next step — meeting booked, ticket created, return label generated.
- Compliance — the invisible guardrails (PCI/HIPAA/GDPR) done right.
Score 0–2 per behavior. Auto-pass items detectable by system events (e.g., next-step scheduled). Run weekly calibration (same five calls, different reviewers) and coach one call per agent, per week. Your scripting and snippet library should update every week based on QA patterns — not once a quarter. That’s how AHT drops 10–20% while CSAT rises.
5) Analytics Without CSV Hell — An Events Model Leaders Can Trust
Executives don’t want dashboards; they want permission to make decisions. You get that by designing a data model that survives audit and is simple enough to defend in a boardroom. The nucleus is an events schema: CallStarted, Connected, Transferred, Wrapped, Dispositioned — each carrying Agent, Queue, Campaign, Customer, and CRM object joins. Everything else (intraday ops, cohort trends, revenue attribution) becomes a view over those events.
The three views that matter
- Operational (intraday): SL/ASA by queue, adherence, live backlog, transfer reasons.
- Cohort (weekly): AHT/FCR/CSAT by intent/agent/campaign; coached vs uncoached.
- Business (attribution): meetings/deals per 100 connects, cost/contact vs deflection, revenue/contact.
If a metric can’t be reproduced across these layers, it doesn’t go on the exec page. With ActiveCalls, events stream via webhooks or scheduled exports into your warehouse (BigQuery/Snowflake), and CRM connectors keep dispositions tied to real outcomes (tickets resolved, payments collected, opportunities created). That’s “one source of truth” in practice, not a slide.
6) Security, Compliance & Global Scale — Pass Review, Sleep Better
Nothing burns a deal faster than a failed security review. Bake controls into the platform so sales cycles shorten and audits become boring. Minimum bar: TLS/SRTP, SSO/SAML, RBAC, immutable audit logs, separate encryption keys for recordings, and an incident runbook with named roles. For PCI, use pause/resume or field-level redaction; for HIPAA, BAAs and least-privilege access; for GDPR, lawful basis, consent handling, and data residency options. Globally, rely on multi-region edges, carrier diversity, and health-checked failover so numbers in Tokyo don’t depend on a single US route at 3am.
7) Call Center Software FAQs
When reliability stops being a meeting topic, everything else gets easier: customers wait less, agents perform with less stress, and leaders finally see the straight line from voice → outcomes. If you’re done with downtime, build on a platform that treats reliability as a design constraint, not an SLA footnote. That’s the difference between “phones seem fine today” and “we ship revenue on schedule.”






